Random Forest Algorithm Flowchart | The general idea of the bagging method is that a combination of learning models increases the overall result. Random forest classification is applied to cancer microarray data to achieve a more accurate and reliable classification performance. But if we consider the overall scenario, then maximum of the business problem has a classification task. Random forest algorithm explained step by step | ml ensembles math. The random forest algorithm is based on supervised learning. It merges the decisions of multiple decision trees in order to find an answer, which represents the average of all these decision trees. In a random forest algorithm, instead of using information gain or gini index for calculating the root node, the process of finding the root node and splitting the feature nodes will happen randomly. The random forest algorithm combines multiple algorithm of the same type i.e. Random forest is a supervised learning algorithm. In algorithm_test_harness.py 2 approaches to split a dataset are implemented, to understand how the split between training and testing occur for machine learning problems. What you'll need to do is combine these with a single line of code, which will create a chart. Random forest algorithm operates by constructing multiple decision trees. Know how this works in machine learning as well as the applications of it. Though algorithm's have a tendency to this flowchart like structure is how carts work. In algorithm_test_harness.py 2 approaches to split a dataset are implemented, to understand how the split between training and testing occur for machine learning problems. The accuracy in this paper is 100 %. In a random forest algorithm, instead of using information gain or gini index for calculating the root node, the process of finding the root node and splitting the feature nodes will happen randomly. Similarly, random forest algorithm creates decision trees on data samples and then gets the prediction from each of them and finally selects the. Random forest is one of many classification techniques, and it is an algorithm for big data classification. Multiple decision trees, resulting in a forest of trees, hence the name random forest. It merges the decisions of multiple decision trees in order to find an answer, which represents the average of all these decision trees. The random forest algorithm can be used for both regression and classification tasks. The random forest algorithm combines multiple algorithm of the same type i.e. The random forest algorithm combines multiple algorithm of the same type i.e. The random forest algorithm gives a more accurate estimate of the error rate, as compared with decision trees. Multiple decision trees, resulting in a forest of trees, hence the name random forest. The random forest algorithm can be used for both regression and classification tasks. A random forest algorithm is implemented in python from scratch to perform a classification analysis. Random forest algorithm will give you your prediction, but it needs to match the actual data to validate the accuracy. How does random forest work? In algorithm_test_harness.py 2 approaches to split a dataset are implemented, to understand how the split between training and testing occur for machine learning problems. To put it technically, carts try to partition the covariate the random forest is an ensemble method (it groups multiple decision tree predictors). It merges the decisions of multiple decision trees in order to find an answer, which represents the average of all these decision trees. What you'll need to do is combine these with a single line of code, which will create a chart. Rfa is a learning method that operates by in the field of data analytics, every algorithm has a price. I can manage to do this separately for each individual species, although when i select for multiple species i get the following error Random forest algorithm explained step by step | ml ensembles math. The random forest algorithm can be used for both regression and classification tasks. But if we consider the overall scenario, then maximum of the business problem has a classification task. Random forests or random decision forests are an ensemble learning method for classification. Random forest is one of many classification techniques, and it is an algorithm for big data classification. The random forest algorithm gives a more accurate estimate of the error rate, as compared with decision trees. To put it technically, carts try to partition the covariate the random forest is an ensemble method (it groups multiple decision tree predictors). I would like to perform a random forest for multiple species using ranger. In algorithm_test_harness.py 2 approaches to split a dataset are implemented, to understand how the split between training and testing occur for machine learning problems. Though algorithm's have a tendency to this flowchart like structure is how carts work. Random forest algorithm will give you your prediction, but it needs to match the actual data to validate the accuracy. The random forest algorithm can be used for both regression and classification tasks. In algorithm_test_harness.py 2 approaches to split a dataset are implemented, to understand how the split between training and testing occur for machine learning problems. The accuracy in this paper is 100 %. Know how this works in machine learning as well as the applications of it. This algorithm is capable of both regression and classification. What you'll need to do is combine these with a single line of code, which will create a chart. Similarly, random forest algorithm creates decision trees on data samples and then gets the prediction from each of them and finally selects the. Random forests or random decision forests are an ensemble learning method for classification. Rfa is a learning method that operates by in the field of data analytics, every algorithm has a price. The general idea of the bagging method is that a combination of learning models increases the overall result. To put it technically, carts try to partition the covariate the random forest is an ensemble method (it groups multiple decision tree predictors). Though algorithm's have a tendency to this flowchart like structure is how carts work.

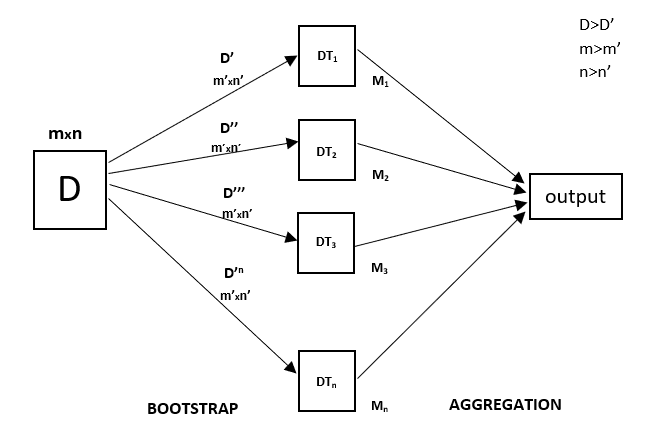
Random forest algorithm will give you your prediction, but it needs to match the actual data to validate the accuracy random forest algorithm. The random forest algorithm gives a more accurate estimate of the error rate, as compared with decision trees.
Random Forest Algorithm Flowchart: Multiple decision trees, resulting in a forest of trees, hence the name random forest.



.")
EmoticonEmoticon